U.S. president Donald Trump called Daylight Saving Time "very costly to our nation" and "inconvenient" in December. Today the Washington Post remembers he'd vowed his Republican party would use their "best efforts" to eliminate it.
But it's still proving to be politically difficult...
Polls have shown that most Americans oppose the time shifts but disagree on what should replace them... [U.S. political leaders] also say they are grappling with whether the nation should permanently move the clocks forward one hour, an idea championed by lawmakers on the coasts who say it would allow for more sunshine during the winter, or remain on year-round standard time, which is favored by neurologists who say it aligns with our circadian rhythms. That decision would rest with Congress, not the president. The split often reflects regional, not political, differences, based on where time zones fall; a year-round "spring forward" would mean winter sunrises that could creep past 9 a.m. in cities such as Indianapolis and Detroit, prompting many local lawmakers to oppose the idea...
[A 2022 Senate vote to make Daylight Saving Time permanent] awoke a new lobbying effort from advocates such as the American Academy of Sleep Medicine, which warned that year-round daylight saving time would be unhealthy, citing risks such as higher rates of obesity or metabolic dysfunction. Some researchers warned of a condition dubbed "social jetlag," saying that internal body clocks and rhythms would be persistently misaligned if human clocks were permanently set forward an hour. The concerted resistance from the health groups — which some congressional aides jokingly referred to as "Big Sleep" — helped kill the measure in the House and has contributed to a stalemate over how to proceed...
Today, roughly two-thirds of Americans want to end the clock changes, polls show. But even those Americans don't agree on what should come next. An October 2023 YouGov poll found that 33 percent of respondents wanted year-round daylight saving time, 23 percent wanted permanent standard time, and 9 percent had no preference. The remainder weren't sure or preferred to remain on the current system... The political fight is far from over, with Trump allies such as Sen. Tommy Tuberville (R-Alabama) pledging to keep pushing for year-round daylight saving time. Some congressional Republicans also have privately called for a hearing in front of the House Energy and Commerce Committee, with hopes of advancing the Sunshine Protection Act.
Said it before, will say it again. This fall, we should fall back 1/2 an hour and meet Indian (and a chunk of Australia) on the half-hour and split the difference of Daylight Savings.
Scientists have long suspected a connection between the dust and poor respiratory health near the Salton Sea in California. But after years of research, recent findings have offered surprising new insights: The prime suspect is a naturally occurring toxin, embedded in the dust.
A previously unknown contributor to the popular open-source Android app store F-Droid repeatedly pressured its developers to push a code update that would have introduced a new vulnerability to the software, in what one of the developers described on Mastodon as a “similar kind of attempt as the Xz backdoor.”
As the fallout of the Xz backdoor continues to rock the open source software community, people working on open source software are realizing (and reiterating) that a culture in which people often feel entitled to constant updates and additional features from volunteer coders presents a pretty large attack surface.
In the case of the Xz backdoor, a malicious actor was able to pressure the owner of a widely-used Linux compression utility called Xz Utils into making them a trusted maintainer of the project. They did this in part by arguing that the owner was letting the community of users down because they weren’t pushing new features and updates often enough, in the eyes of this malicious coder. You can read our full rundown here
Tuesday, Hans-Christoph Steiner, a longtime developer of F-Droid, explained that a very similar situation nearly led F-Droid to push an update that would have introduced a security vulnerability into the product three years ago: “Three years ago, F-Droid had a similar kind of attempt as the Xz backdoor,” he posted on Mastodon. “A new contributor submitted a merge request to improve the search, which was oft requested but the maintainers hadn't found time to work on. There was also pressure from other random accounts to merge it. In the end, it became clear that it added a SQL injection vulnerability. In this case, we managed to catch it before it was merged. Since similar tactics were used, I think it’s relevant now.”
Other open source developers and security experts have pointed to the dynamic of bullying and the general reliance on a small number of volunteer developers. They explained that it’s a problem across much of the open source software ecosystem, and is definitely a problem for the large tech companies and infrastructure who rely on these often volunteer-led projects to build their for-profit software on top of.
💡
Do you know anything else about another incident of bullying leading to a vulnerability in the FOSS community? I would love to hear from you. Using a non-work device, you can message me securely on Signal at +1 202 505 1702. Otherwise, send me an email at jason@404media.co.
Glyph, the founder of the Twisted python networking engine open source project, said the Xz Utils pressure campaign should “cause an industry-wide reckoning with the common practice of letting your entire goddamn product rest on the shoulders of one overworked person having a slow mental health crisis without financially or operationally supporting them whatsoever. I want everyone who has an open source dependency to read this message.”
They then linked to an email in the Xz Utils listserv that shows a likely sockpuppet account arguing “Progress will not happen until there is new maintainer … The current maintainer lost interest or doesn't care to maintain anymore. It is sad to see for a repo like this.”
Meredith Whitaker, the president of Signal, said “I keep brooding on the way the xz backdoor was enabled in significant part via weaponizing the FOSS [free and open source software culture of shitty behavior and abuse.”
“What is striking is that the uncool, mean standards of FOSS conduct that many of us have decried for years, and that many defended as authentic, tough, etc., ended up not just being exclusionary loser behavior, but a significant attack surface.”
In that thread, the now-banned developer who wanted to push code that would have added a vulnerability repeatedly demanded that their new feature be integrated into the live product immediately. As Steiner said, the new feature would have changed how people searched for apps on F-Droid. The potentially malicious user argued “the search results are pretty unusable currently,” and proposed new code. Over the course of months, that user kept writing things like “do we want to merge now?,” meaning push the code live and “I’d really like for this to get into the next release.”
When other users, including Steiner, pointed out that they still needed to review the code, tweak it, or make adjustments to improve its functionality, the original user became angry, and other users backed the original poster.
One other user, for example, argued “I’d like to get this merged for a release soon … is this perfect? No, but it doesn’t need to be. It just needs to be better than what we have now.”
“The second big reason why I think this should be merged soon, is about encouraging new contributors,” the person arguing for inclusion added. “And not by saying ‘we welcome contributions’ and then never allowing any changes because they are not perfect. If people never get anything merged they'll most likely never spend any more time diving deeper into the codebase and tackling more complex tasks later on.”
The original poster wrote “at risk of sounding rude, I believe that this is a great change as it stands, and we have spent too long debating alternative implementations that I am not going to work on (I have a full-time job, and I will not spend my time on work that I believe to be worse than what I have already made). Please consider leaving new details to a future discussion or change and merging what we have now.”
Steiner argued that the code wasn’t ready to go, and that pushing it could “break things for many 10s of thousands of users.”
“I haven't seen any evidence that there is a sudden crisis caused by bad search. It’s been that way since the beginning. So we have time to get this right,” Steiner wrote.
The original poster continued to pressure Steiner and other maintainers of the code, and eventually wrote “nah man, I’m tired of this … I'm not coming back to this project until I see that contributions made in good faith are welcomed instead of fought every step of the way.”
When Steiner was finally able to audit the code, he found that it would have introduced a vulnerability that would have allowed for SQL injections, which is a very basic type of hack that could have crashed the app and would have also potentially introduced other problems. Steiner wrote at the time that he was unsure whether this was actively malicious or just sloppy, but noted that it was a “security risk” either way.
“I wonder if this was an attempt to insert a SQL injection vuln? Or am I just paranoid?,” he wrote. “Anyone know anything about the original submitter?”
Steiner wrote this week that the original coder deleted their account as soon as F-Droid’s maintainers attempted to review the code, and that he thinks that the user’s behavior, as well as “all the attention from random new accounts” has led him to believe “it could be a deliberate attempt to insert the vuln.”
In this case, the vulnerability ultimately wasn’t pushed to a live product, but it’s a very specific example of the types of pressures and culture that open source projects are constantly dealing with. (An aside: While on the F-Droid forum, I happened to also see two long threads in which a user said Steiner was acting with “scandal behavior” and deep bias because F-Droid had failed to properly implement official support for the constructed artificial language Esperanto into the app; Steiner repeatedly explained that Android itself did not support Esperanto and that was the issue.)
Regardless of intent, Steiner wrote that “clear communication definitely suffers when maintainers are overloaded, stressed out and feel ganged up on. I think that's another key takeaway from this current incident. For a well resourced actor, it is not too hard to social engineer themselves into a trusted position when projects get into that position. That happens all too often, unfortunately.”
A 2006 image from Lebanon, taken by AP photographer Ben Curtis. The photo would quickly be accused of being posed.
In 2006, AP photographer Ben Curtis in 2006 took a photo of a Mickey Mouse doll laying on the ground in front an apartment building that had been blown up during Israel’s war against Hezbollah in Lebanon.
Curtis was a war reporter and this image was one of nine images he transmitted that day. He’d traveled with a number of other reporters in a press pool as a way of insuring collective safety, and had limited time on the ground. He described the city as mostly empty, and the apartment building that had just been detonated as having been evacuated.
Soon after that, the photo’s success lead other photographers to start seeking out similar images of toys discarded beside exploded apartments. As more of these images started to get published, many began to ask questions as to whether these photos were being staged: had the photographers put these toys into the frames of these images?
Similar images to Curtis’ started to appear in war photos.
Errol Morris talked to Curtis at length about the controversy surrounding that photo. Morris raises the point that the photo Curtis submitted didn’t say anything about victims. Nonetheless, readers could deduce, from the two symbols present in the image, that a child was killed in that building. Curtis notes that the caption describes only the known facts: it doesn’t say who the toy belonged to, doesn’t attempt to document casualties. Curtis didn’t know: the building was empty, many people had already fled the city.
Morris and Curtis walked through the details and documentation of that day, and I am confident Curtis found the doll where it was. But for the larger point of that image, no manipulation was needed. It said exactly what anyone wanted it to say.
It wasn’t the picture, it was the caption. The same image would be paired with commentary condemning Israel and editorials condemning Hezbollah. Some presented it as evidence of Israeli war crimes; others suggested it was evidence of Hezbollah’s use of human shields.
We are in the midst of a disinformation crisis. I didn’t select this example to make any kind of political point, as there are certainly people who could address that situation better than I could. I show it because 2006 marked a turning point in the history of digital manipulation. Because another Photoshopped image, found to be edited in manipulative ways, came to be circulated in major newspapers around the world.
Adnan Hajj’s photos of Beirut. Original to the left, altered version to the right.
Reuters photographer Adnan Hajj used the photoshop clone stamp tool to create and darken additional plumes of smoke. He submitted images where he copied and pasted fighter jets and added missile trails. Hajj has maintained that he was merely cleaning dust from the images. I don’t know Hajj’s motives. I can say that I have cleaned dust from images and it never introduced a fighter jet.
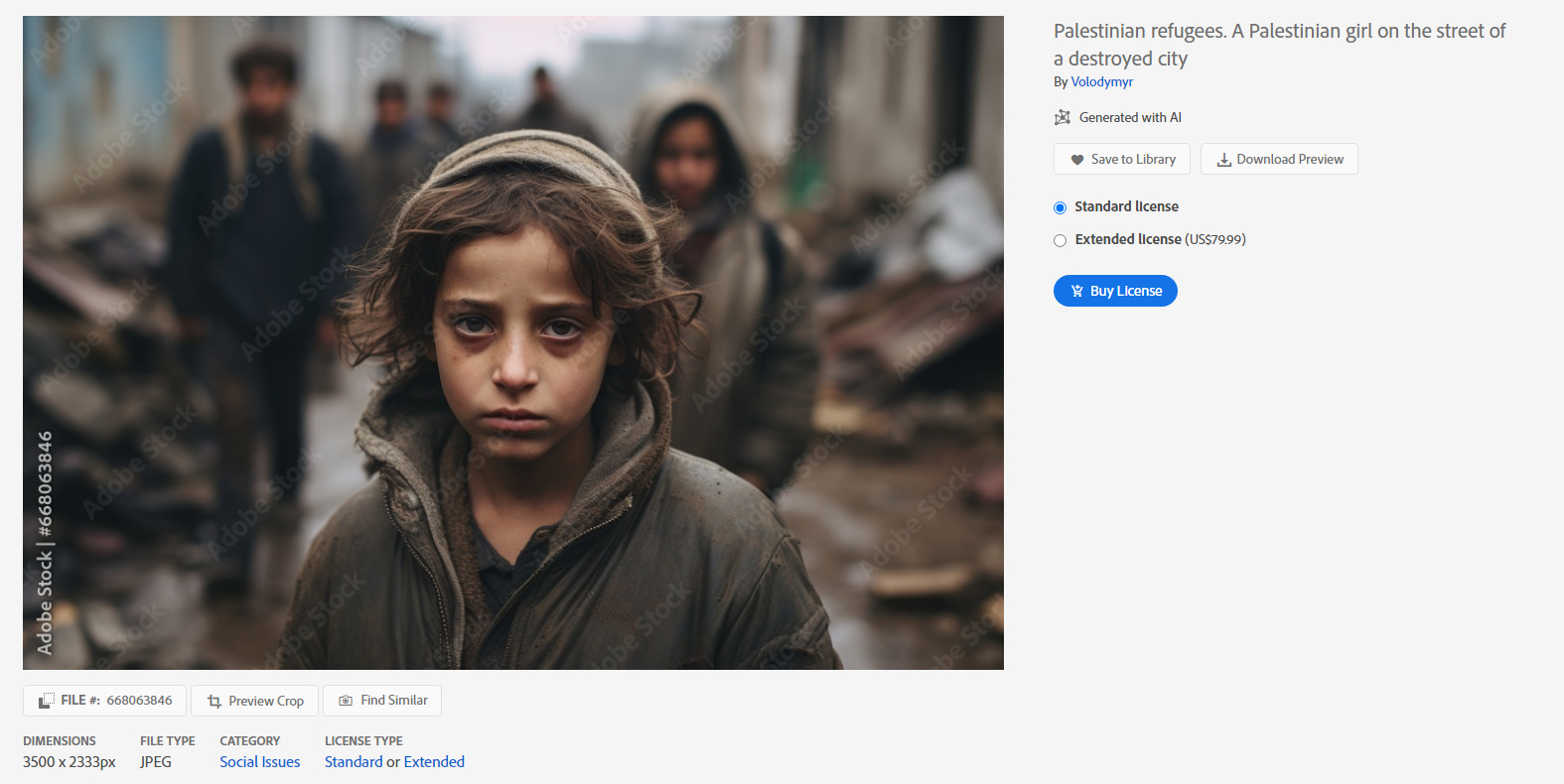
Today, similar imagery is being sold related to Gaza. This image of a teddy bear on the streets of a bombed city is presented when you search Adobe Stock photographs for pictures of Palestinians.
An AI generated image of a teddy bear in a bombed out city.
Adobe’s stock photo website is a marketplace where independent photographers and illustrators sell images. Adobe, which owns a generative AI tool called Firefly, has stated that AI generated images are fine to sell if creators label them correctly. This photo is labeled as “Generated with AI,” keeping in line with Adobe’s policies.
But the same photo has no restrictions on its use. Images of the bear could show up on news sites, blogs, or social media posts without any acknowledgement of its actual origins. This is already happening with many of these images. Adobe might argue that this is a computer-assisted illustration: a kind of hyperrealistic editorial cartoon. Most readers won’t see it that way. And other images would struggle to fit that definition, such as this one, which is labeled as a Palestinian refugee:
This refugee doesn’t exist. She is an amalgamation of a Western, English-language conception of refugees and of Gaza, rendered in a highly cinematic style. The always-brilliant Kelly Pendergrast put it this way on X:
Perhaps the creator of this image wanted to create compelling portraits of refugees in order to humanize the trauma of war. Or maybe they simply thought this image would sell. Perhaps they even thought to generate these images in order to muddy the waters of actual photojournalists and any horrors they might document. All of these have precedents long before AI or digital manipulation. And none of them matter. What matters is what these images do to channels of information.
They’re noise.
Noisy Channels
AI images are swept up into misinformation and disinformation. Those prefixes suggest the opposite of information, or it least, information that steers us astray. But maybe we should zoom out even further: what is information?
Claude Shannon was working at Bell Labs, the American telephone network where he did much of his work in the 1940s, when he sketched out a diagram of a communication system. It looked like this:
Claude Shannon, Diagram of a Communication System.
Information starts from a source. It moves from that source into a transmitter. Shannon was looking at telephones: you have something you want to say to your friend. You are the information source. You bring up a device — the telephone, an email, a passenger pigeon — and you use that device to transmit that message. Along the way this signal moves into the ether between the transmitter and the sender.
That’s when noise intervenes. Noise is the opposite of information, or the removal of information. In a message, it is the flipping of a symbol of communication in a way that distorts the original intention.
There are two sources of noise in this visualization. The first is noise from outside the system. The second is inside, when information breaks down in the transmission.
This could be a fog obscuring a flashing light meant to guide a pilot. There could be a degradation of signal, such as a glitched image occurring somewhere between the transmission from a digital camera into our hard drives. It started by understanding hiss over the telephone, but this was soon expanded to mean basically anything that interferes with the information source arriving intact to its destination.
Today, one of those things that changes the meaning of symbols is algorithms, ostensibly designed to remove noise from signal by amplifying things the receiver wants to see. In fact, they’re as much a form of interference with communication as a means of facilitating it.
Social media algorithms prioritize the wrong side of communication. They define noise as information that distracts the user from the platform. We tend to think these platforms are there to helps us share. If we don’t share, we think they are there to help us read what is shared.
None of that is the actual structure of the system. The system doesn’t show us what we sign up to see. It doesn’t share what we post to the people we want to see it.
The message in that system is advertising. Most of what we communicate on social media is considered noise which needs to be filtered out in order to facilitate the delivery of that advertising. We are the noise, and ads are the signal.
They de-prioritize content that brings people outside of the site, emphasize content that keeps us on. They amplify content that triggers engagement — be it rage or slamming the yes button — and reduce content that doesn’t excite, titillate, or move us.
It would be a mistake to treat synthetic images in isolation from their distribution channels. The famous AI photo of Donald Trump’s arrest is false information, a false depiction of a false event. The Trump images were shared with full transparency. As it moved through the network, noise was introduced: the caption was removed.
Original post of the Donald Trump arrest photos, which were posted as satire but then decontextualized and recirculated as real.
It isn’t just deepfakes that create noise in the channel. Labeling real images as deepfakes introduces noise, too. An early definition of disinformation — from Joshua Tucker & others in 2018, defined it as “the types of information that one could encounter online that could possibly lead to misperceptions about the actual state of the world.” It’s noise — and every AI generated image fits that category.
AI generated images are the opposite of information: they’re noise. The danger they pose isn’t so much what they depict. It’s that their existence has created a thin layer of noise over everything, because any image could be a fraud. To meet that goal — and it is a goal — they need the social media ecosystem to do their work.
Discourse Hacking
For about two years in San Francisco my research agenda included the rise of disinformation and misinformation: fake news. I came across the phrase “discourse hacking” out in the ether of policy discussions, but I can’t trace it back to a source. So, with apologies, here’s my attempt to define it.
Discourse Hacking is an arsenal of techniques that can be applied to disturb, or render impossible, meaningful political discourse and dialogue essential to the resolution of political disagreements. By undermining even the possibility of dialogue, you see a more alienated population, unable to resolve its conflicts through democratic means. This population is then more likely to withdraw from politics — toward apathy, or toward radicalization.
As an amplifying feedback loop, the more radicals you have, the harder politics becomes. The apathetic withdraw, the radicals drift deeper into entrenched positions, and dialogue becomes increasingly constrained. At its extreme, the feedback loop metastasizes into political violence or democratic collapse.
Fake news isn’t just lies, it’s lies in true contexts. It was real news clustered together alongside stories produced by propaganda outlets. Eventually, all reporting could be dismissed as fake news and cast it immediately into doubt. Another — (and this is perhaps where the term comes from) — was seeding fake documents into leaked archives of stolen documents, as happened with the Clinton campaign.
The intent of misinformation campaigns that were studied in 2016 was often misunderstood as a concentrated effort to move one side or another. But money flowed to right and left wing groups, and the goal was to create conflict between those groups, perhaps even violent conflict.
It was discourse hacking. Russian money and bot networks didn’t help, but it wasn’t necessary. The infrastructure of social media — “social mediation” — is oriented toward the amplification of conflict. We do it to ourselves. The algorithm is the noise, amplifying controversial and engaging content and minimizing nuance.
Expanding the Chasm
Anti-semitism and anti-Islamic online hate is framed as if there are two sides. However:
Every individual person is a complex “side” and so there are millions
The impossibility of dialogue between Gaza and Israel is not a result of technology companies. But the impossibility of dialogue between many of my friends absolutely is. Emotions are human, not technological. Our communication channels can only do so much, in the best of times, to address cycles of trauma and the politics they provoke.
Whenever we have the sensation that “there’s just no reasoning with these people,” we dehumanize them. We may find ourselves tempted to withdraw from dialogue. That withdrawal can lead to disempowerment or radicalization: either way, it’s a victory for the accelerationist politics of radical groups. Because even if they radicalize you againstthem, they’ve sped up the collapse. Diplomacy ends and wars begin when we convince ourselves that reasoning-with is impossible.
To be very clear, sometimes reasoning-with is impossible, and oftentimes that comes along with guns and fists or bombs. Violence comes when reason has been extinguished. For some, that’s the point — that’s the goal.
Meanwhile, clumping the goals and beliefs of everyday Israelis with Netanyahu and setting them together on “one” side, then lumping everyday Palestinians with Hamas on another, is one such radicalizing conflation. It expands the chasm in which reason and empathy for one another may still make a difference. The same kluge can be used to normalize anti-Semitism and shut down concerns for Palestinian civilians.
The goal of these efforts is not to spread lies. It’s to amplify noise. Social media is a very narrow channel: the bandwidth available to us is far too small for the burden of information we task it with carrying. Too often, we act as though the entire world should move through their wires. But the world cannot fit into these fiber optic networks. The systems reduce and compress that signal to manage. In reduction, information is lost. The world is compressed into symbols of yes or no: the possibly-maybe gets filtered, the hoping-for gets lost.
Social media is uniquely suited to produce this collapse of politics and to shave down our capacity for empathy. In minimizing the “boring” and mundane realities of our lives that bind us, in favor of the heated and exclamatory, the absurd and the frustrating, the orientations of these systems is closely aligned with the goals of discourse hacking. It’s baked in through technical means. It hardly matters if this is intentional or not — The Purpose of a System is What it Does.
Deep fakes are powerful not only because they can represent things that did not occur, but because they complicate events which almost certainly did. We don’t need to believe that a video is fake. If we decide that it is beyond the scope of determination, it can be dismissed as a shared point of reference for understanding the world and working toward a better one. It means one less thing we can agree on.
But people use images to tell the stories they want to tell, and they always have. Images — fake or real — don’t have to be believed as true in order to be believed. They simply have to suggest a truth, help us deny a truth, or allow a truth to be simplified.
Pictures do not have to be true to do this work. They only have to be useful.
(This is an extended version of a lecture on misinformation given to the Responsible AI program at ELISAVA Barcelona School of Design and Engineering on November 15, 2023.)
"Deep fakes are powerful not only because they can represent things that did not occur, but because they complicate events which almost certainly did. We don’t need to believe that a video is fake. If we decide that it is beyond the scope of determination, it can be dismissed as a shared point of reference for understanding the world and working toward a better one."
In a calm morning in March 1968, a shipment carrying the latest Korgs, Moogs and Hammond organs set off from Baltimore harbour, heading for an exhibition in Rio de Janeiro. The sea was steady, the containers safely attached. And yet later that same day, the ship would inexplicably vanish.
A few months later, it finally reappeared. Somehow, the ship had been marooned on the São Nicolau island of Cabo Verde (now Cape Verde, but then a Portuguese territory 350 miles off the west coast of Africa). The crew were nowhere to be seen and the cargo was commandeered by local police. But when it was found to contain hundreds upon hundreds of keyboards and synths, an anti-colonial leader called Amílcar Cabral declared the instruments should be distributed equally among the archipelago’s schools.
Overnight, a whole generation of young Cabo Verdeans gained free access to cutting-edge music gear. According to Frankfurt-based rarities label Analog Africa, this bizarre turn of fate can be directly credited with inspiring the island’s explosion of newly electrified sounds following independence in 1975, and has now been documented on its on its latest compilation, Space Echo – The Mystery Behind The Cosmic Sound Of Cabo Verde.
The synths, it is claimed, helped modernise the indigenous folk dances morna and coladeira, as well as funaná – an African style previously outlawed by the Portuguese – by figures such as star arranger Paulino Vieira, one of the schoolkids who benefited from the haul. In Vieira’s music, makeshift percussive contraptions such as the ferrinho (an iron bar scraped with a knife) were layered with Nile Rodgers disco guitars, frisky synth solos and the whirling rhythms of Latin American bolero and salsa. All of it is dazingly repetitive and trippy, coming across like the soundtrack to some sort of lost sci-fi B-movie.
Forward-looking vintage sounds from Africa are enjoying a moment across Europe right now, but Analog Africa founder Samy Ben Redjeb says he set up his label to highlight the hidden scenes on a continent whose music has too often been blurred into one.
“Before it was all just ‘world music’, but people are starting to see that this is just a bullshit word,” he explains. “People are starting to understand that every African region has different sounds and styles of music. We’re starting to break that all down.”
Now, enthusiasts may become familiar with the futuristic, trippy sounds of 1970s and 80s Cape Verde. But what if that cargo had never lost its way? Cabo Verde’s cosmic sound wouldn’t just be steeped in mystery, it wouldn’t even exist. They say most music scenes are born by accident, but it’s rarely as literal as this.
Space Echo is out on Friday 27 May via Analog Africa
When building a new thing, a good first step is to build a thing that does nothing. That way, you at least know you are starting from a good place. If I’m building a component that performs an action, I’ll probably do it in these steps:
Step zero is to write a standalone program to perform the action. This ensures that the action is even possible.
Once I have working code to perform the action, I write a component that doesn’t perform an action. That at least makes sure I know how to build a component.
Next, I register the component for the action, but have the Invoke method merely print the message “Yay!” to the debugger without doing anything else. This makes sure I know how to get the component to run at the proper time.
Next, I fill in the Invoke method with enough code to identify what action to perform and which object to perform it on, print that information to the debugger, and return without actually performing the action. This makes sure I can identify which action is supposed to be done.
Finally, I fill in the rest of the Invoke method to perform the action on the desired object. For this, I can copy/paste the already-debugged code from step zero.
Too often, I see relatively inexperienced developers dive in and start writing a big complex thing: Then they can’t even get it to compile because it’s so big and complex. They ask for help, saying, “I’m having trouble with this one line of code,” but as you study what they have written, you realize that this one line of code is hardly the problem. The program hasn’t even gotten to the point where it can comprehend the possibility of executing that line of code. I mutter to myself, “How did you let it get this bad?”
Start with something that does nothing. Make sure you can do nothing successfully. Only then should you start making changes so it starts doing something. That way, you know that any problems you have are related to your attempts to do something.